Researchers have developed a new technique to help computers automatically understand product photos from the likes of Amazon.com. This saves time from manually labelling product details like brand, size, colour for every item. The goal is getting computers to extract attributes from all types of product photos. Here are a few points on how Amazon sellers could be wasting time/efforts with keyword stuffing of product images, and how it relates to automated attribute extraction:
- With limited image title space, sellers may stuff as many keywords as possible to try ranking for those searches.
- However, excessive keyword stuffing is ineffective or risks penalisation by Amazon (rank that is). The optimal keywords are ones relevant to accurately describing the product.
- The automated attribute extraction system described in the research aims to predict these descriptive attributes accurately based on the image content.
- If sellers overload images with irrelevant keywords trying to game the system, it likely does not help with ranking. The algorithms are designed to extract the genuine attributes.
- Additionally, the extracted attributes can sometimes reveal aspects not mentioned in the seller-provided titles/descriptions. The algorithms may detect helpful keywords the seller overlooked.
- So rather than trying to override the system’s predictions with excessive keywords, sellers are better off focusing efforts on displaying products clearly and letting the algorithms extract meaningful attributes.
- As computer vision advances, imagery understanding will become increasingly reliable. Relying on technology to parse images reduces manual efforts and provides more consistency.
- Sellers should view automated attribute tagging as an asset, not something to “beat” with keyword stuffing. When used ethically, it can improve search visibility in a scalable way.
Excessive keyword stuffing is often ineffective or counterproductive with modern search algorithms. Sellers should focus on presenting products clearly and enabling automated systems to extract meaningful attributes from images algorithmically.
But let’s get into it…
Challenges in Multi-Category Attribute Extraction
A key challenge is extracting attributes across diverse categories. For example, vocabularies for size in shirts (“small”, “large”) versus diapers (“newborn”, numbers) are totally different. Methods focused on single categories don’t transfer well.
The Key Challenges
The researchers identified 3 big challenges that make this problem really hard:
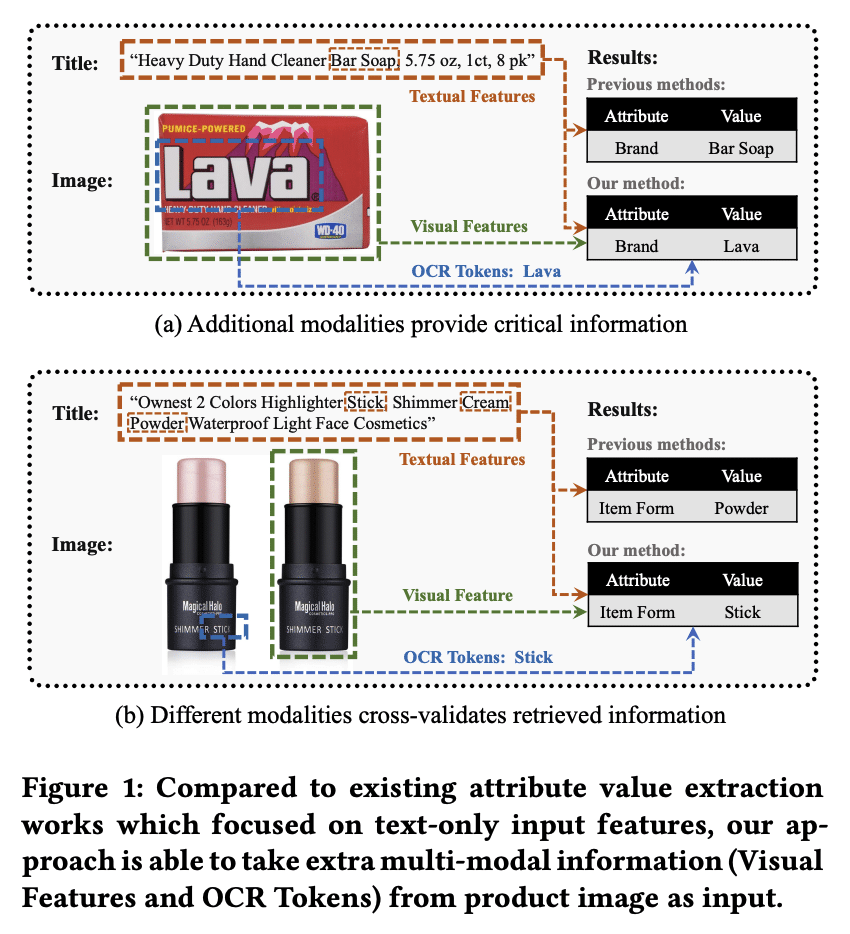
- Connecting the different types of input – photos, text, and text in images.
optical character recognition
- Special vocabulary in product descriptions.
- Totally different attribute values across product types.
These 3 challenges of multi-modal inputs, unique vocabulary, and diverse attribute values across categories are what make automatic product understanding so difficult, especially compared to approaches focused on single product types and text alone. The researchers aimed to address these issues with their model design and training techniques.
The Proposed Model
The researchers designed a new AI model to tackle these challenges. Their model uses something called a transformer. What’s a transformer? It’s a type of machine learning model that’s good at understanding relationships between different types of input data. In this case, the transformer encodes, or represents, three kinds of information:
- The product description text
- Objects detected in the product photo
- Text extracted from the photo using OCR (optical character recognition)
The transformer figures out connections between the visual inputs from the photo and textual inputs from the description and OCR. Next, the decoder part makes predictions. It predicts the attribute values step-by-step, focusing on different parts of the encoded inputs at each step. The decoder outputs a probability distribution over possible tokens (words) at each step. To reduce meaningless nonsense text, the decoder can only output from certain useful tokens, not any random word. By leveraging a transformer and constraining outputs, the model can combine multimodal inputs and generate coherent attribute values tailored to the product category and description.
Using Category-Specific Word Lists
To deal with unique words and phrases for each product type, the model looks up category-specific vocabularies when making predictions. For example, it uses one word list with common size terms for shirts, and a totally different list with size words for diapers. Having these tailored word lists for each category gives the model useful information about which attribute values are likely.
Techniques to Handle Different Categories
The researchers used two key techniques to help the model extract attributes across varied product categories:
- Pick vocabulary based on predicted category – The model first guesses the general product category, then uses the word list for that category to predict attributes.
- Multi-task learning – The model is trained to jointly predict the product category and attribute value. Doing both tasks together improves the learning.
Results
When tested on 14 different Amazon product categories, the model achieved much higher accuracy than approaches using only text. The image, text, and OCR inputs all provided useful signals. Using category-specific vocabularies worked better than generic word lists. This demonstrates the benefits of using multimodal inputs and tailoring predictions to each product category.
Automated Understanding of Product Images
This research allows computers to extract product attributes from images more accurately compared to approaches using just text. It provides a framework for unified reasoning across product photos, descriptions, and image text. The model combines transformers, category-specific knowledge, and multimodal inputs.

Potential Applications
A useful application is automatically optimising large numbers of product images for Amazon sellers. The extracted attributes like brand and size can be added as keywords to improve search rankings.
Future Research
Some future research ideas include:
- Pre-training the model on more product image data
- Modelling relationships between different attributes
- Incorporating product category taxonomies
Overall, this work makes progress on the very hard problem of developing AI that can holistically understand real-world retail images and text. Combining different data types and using category-specific knowledge are important for achieving better accuracy. The research brings us a step closer to automated systems that can intelligently parse product information as humans do based on photos, descriptions, and context. More work remains to expand these capabilities.